What Is Usenet
In a nutshell; it’s basically a bunch of (file) servers that host a ton of information people place onto it. We’re talking about petabytes (1000+ Terabytes) of information. There is very little organization, but it does have a defined structure.
Content is sorted into groups which act as containers for it to be stored and retrieved from. You can think of a group like you might think of a directory on your computer at home. We create directories all the time in efforts to add order and structure to where we keep things (so we can find them later). The thing is, Usenet has no moderation; so you can place content in any group you want. As a result; it’s a lot like what you might expect someone’s hard drive would look like if you gave 5 million people access to it. Basically there is just a ton of crap everywhere.
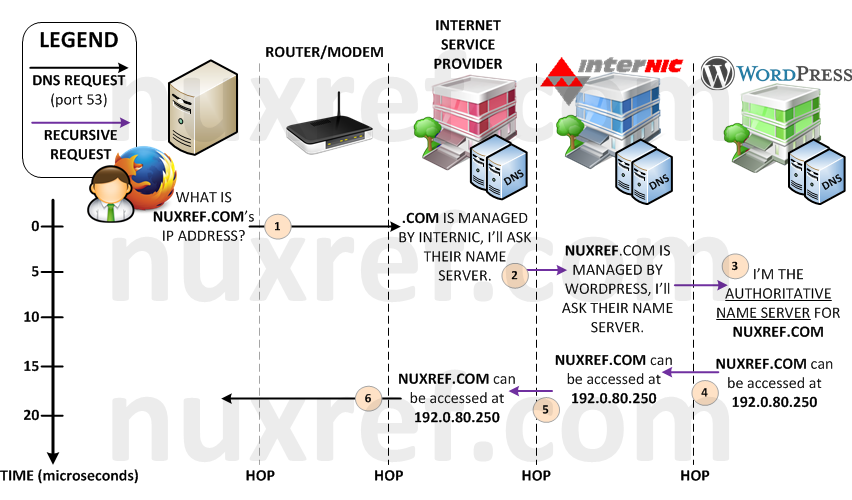
The World Wide Web is similar to this, but instead of groups, we sort things by URLs (web addresses) such as http://nuxref.com. Google uses it’s own web crawlers to scan the entire World Wide Web just to create an index from it. Each website they find, they track it’s name, it’s content, and the language it’s written in. The result from them doing this is: we get to use their fantastic search engine! A search engine that has made our lives incredibly easy by granting us fast and easy accessible information at our fingertips.
The Usenet Indexer
Usenet is a very big world of it’s own and it’s a lot harder to get around in (but not impossible) without anything indexing it. Thankfully Usenet is no where near the size of the World Wide Web which makes indexing it is very possible for a much larger audience! In fact, we can even index it with our personal computer(s) we run at home. By indexing it; we can easily search it for content we’re interested in (much like how we use Google for web page searching).
Since just about anyone can index Usenet, one has to think: Why index Usenet ourselves if someone’s already doing it for us elsewhere? In fact, there are many sites (and tools) that have already done all the indexing (some better than others) of Usenet who are willing to share it with others (us). But it’s important to know: it can take a lot of server power, disk space, and network consumption for these site administrators to constantly index Usenet for us. Since most (if not all) of the sites are just hobbyists doing it for fun, it gets expensive for them to maintain things. For that reason some of them may charge or ask for a donation. If you want to use their services, you should respect their measly request of $8USD to $20USD for a lifetime membership. But don’t get discouraged, there are still a lot of free ones too!
Just keep in mind that Usenet is constantly getting larger; people are constantly posting new content to it every second. You’ll find that the sites that charge a fee are already (relatively) aware of the new changes to Usenet every time you search with it. Others (the free ones) may only update their index a few times a day or so.
Alternatively (the free route), we can go as far as running our own Usenet indexer (such as NewzNab) just as the hobbyists did (mentioned above). NewzNab will index Usenet on a regular basis. With your own indexer, you can choose to just index content that appeals to you. You can even choose to offer your services publicly if you want. Just keep in mind that Usenet is huge! If you do decide to go this route, you’ll find it a very CPU and network intensive operation. You may want to make sure you don’t exceed your Internet Service Providers (ISP) download limits.
Now back to the Google analogy I started earlier: When you find a link on Google you like, you simply click on it and your browser redirect you to the website you chose; end of story. However, in the Usenet Indexing world, once you find something of interest, the Usenet Indexer will provide you with an NZB File. An NZB file is effectively a map that identifies where your content can be specifically located on Usenet (but not the data itself). An NZB file to Usenet is similar to what a Torrent file is to a BitTorrent Client. Both NZB and Torrent files provide the blueprints needed to mine (acquire) your data. Both NZB and Torrent files require a Downloader to preform the actual data mining for you.
The Downloader
The Downloader can take an NZB File it’s provided and then uses it to acquire the actual data it maps to. This is the final piece of the puzzle!
Of the list below, you really only need to choose 1 Downloader. I just listed more then 1 to give you alternatives to work with. My personal preference is NZBGet because it is more flexible. But it’s flexibility can also be very confusing (only at first). Once you get over it’s learning curve and especially the initial configuration; it’s a dream to work with. Alternatively SABnzbd may be better for the novice if your just starting off with Usenet and don’t want to much more of a learning curve then you already have.
Either way, pick you poison:
| Title | Package | Details |
|---|---|---|
| NZBGet | rpm/src | NZBGet is written in C++ and designed with performance in mind to achieve maximum download speed by using very little system resources. Community / Manual **Note: I created this patch in a recent update rebuild (Jul 17th, 2014) to fix a few directory paths so the compression tools (unrar and 7zip) can work right away. I also added these compression tools as dependencies to the package so they’ll just be present for you at the start. **Note: I also created this patch in a recent update rebuild (Nov 9th, 2014) to allow the RC Script to take optional configuration defined in /etc/sysconfig/nzbget. You can install NZBGet using the steps below:
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/nuxref-repository/
# Install NZBGet
yum install -y nzbget
--enablerepo=nuxref
--enablerepo=nuxref-shared
# Grab Template
cp /usr/share/nzbget/nzbget.conf ~/.nzbget
# Protect it
chmod 600 ~/.nzbget
# Start it Up (as a non-root user):
nzbget -D
# You should now be able to access it via:
# http://localhost:6789/
|
| SABnzbd | n/a | SABnzbd is an Open Source Binary Newsreader written in Python. Community / Manual Note:I have not packaged this yet, but will probably eventually get around to it. For now it can be accessed from it’s repository on GitHub, or you can quickly set it up in your environment as follows:
# There is no RPM installer for this one, we just
# fetch straight from their repository.
# Install git (if it's not already)
yum install -y git
# Grab a snapshot of SABnzbd
git clone https://github.com/sabnzbd/sabnzbd.git SABnzbd
# Start it Up (as a non-root user):
python SABnzbd/SABnzbd.py
--daemon
--pid $(pwd)/SABnzbd/sabnzbd.pid
# You should now be able to access it via:
# http://localhost:8080/
|
Automated Index Searchers
These tools search for already indexed content you’re interested in and can be configured to automatically download it for you when it’s found. It itself doesn’t do the downloading, but it will automate the connection between your chosen Indexer and Downloader (such as NZBGet or SABnzbd). For this reason, these tools do not actually search Usenet at all and therefore have very little overhead on your system (or NAS drive).
| Title | Package | Details |
|---|---|---|
| Sonarr |
rpm/src | Automatic TV Show downloader Formally known as NZBDrone; it has since been changed to Sonarr. This was only made possible because of the blog I wrote on mono v3.x .
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/nuxref-repository/
# Installation of this plugin:
yum install -y sonarr
--enablerepo=nuxref
--enablerepo=nuxref-shared
# Start it Up (as a non-root user):
nohup mono /opt/NzbDrone/NzbDrone.exe &
# You should now be able to access it via:
# http://localhost:8989/
|
| Sick Beard |
n/a | (Another) Automatic TV Show downloader
Note:I have not packaged this yet, but will probably eventually get around to it. For now it can be accessed from it’s repository on GitHub, or you can quickly set it up in your environment as follows: # Install git (if it's not already) yum install -y git # Grab a snapshot of Sick Beard # Note that we grab the master branch, otherwise we default # to the development one. git clone -b master https://github.com/midgetspy/Sick-Beard.git SickBeard # Start it Up (as a non-root user): python SickBeard/SickBeard.py --daemon --pidfile $(pwd)/SickBeard/sickbeard.pid # You should now be able to access it via: # http://localhost:8081/ |
| CouchPotato |
n/a | Automatic movie downloader
Note:I have not packaged this yet, but will probably eventually get around to it. For now it can be accessed from it’s repository on GitHub, or you can quickly set it up in your environment as follows: # Install git (if it's not already) yum install -y git # Grab a snapshot of CouchPotato git clone https://github.com/RuudBurger/CouchPotatoServer.git CouchPotato # Start it Up (as a non-root user): python CouchPotato/CouchPotato.py --daemon --pid_file CouchPotato/couchpotato.pid # You should now be able to access it via: # http://localhost:5050/ |
| Headphones |
n/a | Automatic music downloader
Note:I have not packaged this yet, but will probably eventually get around to it. For now it can be accessed from it’s repository on GitHub, or you can quickly set it up in your environment as follows: # Install git (if it's not already) yum install -y git # Grab a snapshot of Headphones git clone https://github.com/rembo10/headphones Headphones # Start it Up (as a non-root user): python Headphones/Headphones.py --daemon --pidfile $(pwd)/Headphones/headphones.pid # You should now be able to access it via: # http://localhost:8181/ |
| Mylar |
n/a | Automatic Comic Book downloader
Note:I have not packaged this yet, but will probably eventually get around to it. For now it can be accessed from it’s repository on GitHub, or you can quickly set it up in your environment as follows: # Install git (if it's not already) yum install -y git # Grab a snapshot of Headphones git clone https://github.com/evilhero/mylar Mylar # Start it Up (as a non-root user): python Mylar/Mylar.py --daemon --pidfile $(pwd)/Mylar/Mylar.pid # You should now be able to access it via: # http://localhost:8090/ |
NZBGet Processing Scripts
For those who prefer SABnzbd, you can ignore this part of the blog. For those using NZBGet, one of it’s strongest features is it’s ability to process content it downloads before and after it’s received. The Post Processing (PP) has been specifically one of NZBGet’s greatest features. It allows separation between the the function NZBGet (which is to download content in NZB files) and what you want to do with the content afterwards. Post Processing could do anything such as catalogue what was received and place it into an SQL database. Post Processing could rename the content and sort it for you in separate directories depending on what it is. Post processing can be as simple as just emailing you when the download completed or post on Facebook or Twitter. You’re not limited to just 1 PP Script either, you can chain them and run a whole slew of them one after another. The options are endless.
I’ve taken some of the popular PP Scripts from the NZBGet forum and packaged them in a self installing RPM as well to make life easy for those who want it. Some of these packages require many dependencies and ports to make the installation smooth. Although i link directly to the RPMs here, you are strongly advised to link to my repository with yum if you haven’t already done so.
| Title | Package | Provides | Details |
|---|---|---|---|
| Failure Link | rpm/src | FAILURELINK | If download fails, the script sends info about the failure to indexer site, so a replacement NZB (same movie or TV episode) can be queued up if available. The indexer site must support DNZB-Header “X-DNZB-FailureLink”.
Note: The integration works only for downloads queued via URL (including RSS). NZB-files queued from local disk don’t have enough information to contact the indexer site.
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/repo/
# Installation of this plugin:
yum install -y nzbget-script-failurelink
--enablerepo=nuxref
--enablerepo=nuxref-shared
|
| nzbToMedia | rpm/src | DELETESAMPLES RESETDATETIME NZBTOCOUCHPOTATO NZBTOGAMEZ NZBTOHEADPHONES NZBTOMEDIA NZBTOMYLAR NZBTONZBDRONE NZBTOSICKBEARD |
Provides an efficient way to handle post processing for CouchPotatoServer, SickBeard, Sonarr, Headphones, and Mylar when using NZBGet on low performance systems like a NAS.
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/repo/
# Installation of this plugin:
yum install -y nzbget-script-nzbtomedia
--enablerepo=nuxref
--enablerepo=nuxref-shared
Note: This package includes the removal of the entire PYPKG/libs directory. I replaced all of the dependencies previously defined here with global ones used by CentOS. The reason for this was due to the fact a lot of other packages all share the same libraries. It just didn’t make sense to maintain a duplicate of it all. |
| Subliminal | rpm/src | SUBLIMINAL | Provides a wrapper that can be integrated with NZBGet with subliminal (which fetches subtitles given a filename or filepath). Subliminal uses the correct video hashes using the powerful guessit library to ensure you have the best matching subtitles. It also relies on enzyme to detect embedded subtitles and avoid retrieving duplicates.
Multiple subtitles services are available using:opensubtitles, tvsubtitles, podnapisi, addic7ed, and thesubdb.
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/repo/
# Installation of this plugin:
yum install -y nzbget-script-subliminal
--enablerepo=nuxref
--enablerepo=nuxref-shared
*Note: python-subliminal (what this PP Script is a wrapper too) had some issues I had to address. For one, I eliminated the entire PYPKG/subliminal/libs directory. I replaced all of the dependencies previously defined here with global ones used by CentOS. The reason for this was due to the fact a lot of other packages all share the same libraries. It just didn’t make sense to maintain a duplicate of it all. I am the current maintainer of this plugin and it can be accessed from my GitHub page here. |
| DirWatch | rpm/src | DIRWATACH | DirWatch can watch multiple directories for NZB-Files and move them for processing by NZBGet. This tool is awesome if you have a DropBox account or a network share you want NZBGet to scan! Without this script NZBGet can only be configured to scan one (and only one) directory for NZB-Files.
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/repo/
# Installation of this plugin:
yum install -y nzbget-script-dirwatch
--enablerepo=nuxref
--enablerepo=nuxref-shared
I am the current maintainer of this plugin and it can be accessed from my GitHub page here. |
| TidyIt | rpm/src | TIDYIT | TidyIt integrates itself with NZBGet’s scheduling and is used to preform basic house cleaning on a media library. TidyIt removes orphaned meta information, empty directories and unused content. It’s the perfect OCD tool for those who want to eliminate any unnecessary bloat on their filesystem and media library.
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/repo/
# Installation of this plugin:
yum install -y nzbget-script-tidyit
--enablerepo=nuxref
--enablerepo=nuxref-shared
I am the current maintainer of this plugin and it can be accessed from my GitHub page here. |
| Notify | rpm/src | NOTIFY | Notify provides a wrapper that can be integrated with NZBGet allowing you to notify in just about any supported method today such as email, KODI (XBMC), Prowl, Growl, PushBullet, NotifyMyAndroid, Toasty, Pushalot, Boxcar, Faast, Telegram, Join, and Slack Notifications. It also supports pushing information in HTTP Post request via JSON or XML (SOAP structure). The script can also be used as a standalone tool and called from the
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/repo/
# Installation of this plugin:
yum install -y nzbget-script-notify
--enablerepo=nuxref
--enablerepo=nuxref-shared
I am the current maintainer of this plugin and it can be accessed from my GitHub page here. |
| Password Detector | rpm/src | PASSWORDETECTOR | Password Detector is a queue script that checks for passwords inside of every .rar file of a NZB downloaded. This means that it can detect password protected NZB’s very early before downloading is complete, allowing the NZB to be automatically deleted or paused. Detecting early saves data, time, resources, etc.
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/repo/
# Installation of this plugin:
yum install -y nzbget-script-passworddetector
--enablerepo=nuxref
--enablerepo=nuxref-shared
|
| Fake Detector | rpm/src | FAKEDETECTOR | This is a queue-script which is executed during download, after every downloaded file containing in nzb-file (typically a rar-file). The script lists content of download rar-files and tries to detect fake nzbs. Thus it saves your bandwidth if it detects that the content your downloading if the contents within it fail to pass a series of validity checks.
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/repo/
# Installation of this plugin:
yum install -y nzbget-script-fakedetector
--enablerepo=nuxref
--enablerepo=nuxref-shared
|
| Video Sort | rpm/src | VIDEOSORT | With post-processing script VideoSort you can automatically organize downloaded video files.
# Note: You must link to the NuxRef repository for this to work!
# See: http://nuxref.com/repo/
# Installation of this plugin:
yum install -y nzbget-script-videosort
--enablerepo=nuxref
--enablerepo=nuxref-shared
Note: This package includes the removal of the entire PYPKG/libs directory. I replaced all of the dependencies previously defined here with global ones used by CentOS. The reason for this was due to the fact a lot of other packages all share the same libraries. It just didn’t make sense to maintain a duplicate of it all. |
Mobile Integration
 There are some fantastic Apps out there that allow you to integrate your phone with the applications mentioned above. It can allow you to manage your downloads from wherever you are. A special shout out to NZB 360 who recently had his app pulled from the Google Play Store for no apparent reason and had to set up shop outside. I can say first hand that his application is amazing! You should totally consider it if you have an Android phone.
There are some fantastic Apps out there that allow you to integrate your phone with the applications mentioned above. It can allow you to manage your downloads from wherever you are. A special shout out to NZB 360 who recently had his app pulled from the Google Play Store for no apparent reason and had to set up shop outside. I can say first hand that his application is amazing! You should totally consider it if you have an Android phone.
Usenet Provides
For those who don’t have Usenet already, it does come at an extra cost and/or fee. The cost averages anywhere between $6 to $20 USD/month (anything more and you’re paying to much). The reason for this is because Usenet is a completely isolated network from the Internet. It’s comprised of a completely isolated set of interconnected servers. While the internet is comprised of hundreds of millions of servers all hosting specific content, each Usenet server hosts the entire usenet database… it hosts everything. If anything is uploaded to Usenet, all of the interconnected servers update themselves with their own local copy of it (to serve us). For this to happen, their servers have to have petabytes of storage. The fee they charge you is just going to support their operational cost such as bandwidth, maintenance and the regular addition of storage to their infrastructure. There is very little profit to be made for them at $8 a person. Here is a breakdown of a few servers (in alphabetical order) I’m aware of and support:
| Provider | Server Location(s) |
Notes | Average Cost |
|---|---|---|---|
| Astraweb | US & Europe | Retention: 2158 Days (5.9 Years) | $6.66USD/Month to $15USD/Month see here for details |
| Usenet Server | US | Retention: 2159 Days (5.9 Years) Has a free 14 day trial |
$13.33USD/Month to $14.95USD/Month see here for details |
*Note: Table information was last updated on Jul 14th, 2014. Prices are subject to change as time goes on and this blog post isn’t updated.
**Note: If you have a provider that you would like to be added to this list… Or if you simply spot an error in pricing or linking, please feel free to contact me so I can update it right away.
Why do people use Usenet/Newsgroups?
- Speed: It’s literally just you and another server; a simple 1 to 1 connection. Data transfer speeds will always be as fast as your ISP can carry your traffic to and from the Usenet Server you signed up with. Unlike torrents, content isn’t governed by how many seeders and leechers that have the content available to you. You never have to deal with upload/download ratios, maintain quotas, and or sit idle in someone’s queue who will serve data to you eventually.
- Security: You only deal with secure connections between you and your Usenet Provider; no one else! Torrents can have you to maintaining thousands of connections to different systems and sharing data with them. With BitTorrent setups, tracker are publicly advertising what you have to share and what your trying to download. Your privacy is public to anyone using the same tracker that you’re connected to. Not only that, but most torrent connections are insecure as well which allows virtually anyone to view what you’re doing.
Please know that I am not against torrents at all! In fact, now I’ll take the time to mention a few points where torrents are excel over Usenet:
- Cost: It doesn’t usually cost you anything to use the torrent network. It all depends on the tracker your using of course (some private trackers charge for their usage). But if you’re just out to get the free public stuff made available to us, there are absolutely no costs at all to use this method!
- Availability: Usenet is far from perfect. When someone uploads something onto their Usenet Provider, by the time it propagates this new content to all of the other Usenet Servers, there is a small chance the data will be corrupted. This happens with Usenet all of the time. To compensate for this, Usenet users anticipate corruption (sad but true). These people kindly post Parchive files to Usenet to compliment whatever they previously uploaded. Parchive files work similar to how RAID works; they provide building blocks to reassemble data in the event it’s corrupted. Corruption never happens with Torrents unless the person hosting decides to host corrupted data. Any other scenario would simply be because your BitTorrent Client had a bug in it.
- Retention: As long as someone is willing to seed something, or enough combined leechers can reconstruct what is being shared, then data will always stay alive in the BitTorrent world. However with Usenet, the Usenet Server is hosting EVERYTHING which means it has to maintain a lot data on a lot of disk space! For this reason, a retention period is inevitably met. A time is eventually reached where the Usenet Server purges (erases) older content from these hard disks to make room for the new stuff showing up every day.
Honestly, at the end of the day: both Torrents and Usenet Servers have their pros and cons. We will always continue each weigh them at different levels. What’s considered the right choice for one person, might not be the right one for another. Heck, just use both depending on your situation! 🙂
Source
- Wikipedia’s article explaining what Usenet is.
- NZBGet Official Website
- SABnzbd Official Website
- Sonarr Official Website and it’s GitHub repository.
- CouchPotato (Server) Official Website and it’s GitHub repository.
- Sick Beard Official Website and it’s GitHub repository
- Mylar has no other (official) website other then it’s GitHub repository
- Headphones has no other (official) website other then it’s GitHub repository
- NZB 360 is a fantastic Android Application that you can use to integrate with SABnzbd, NZBGet, CouchPotato, Sick Beard, Sonarr, and Headphones!
- NewzNab is a PHP (v5.3+) based indexer that can allow you to index Usenet (or portions of it) yourself.
- Subliminal NZBGet Post-Process & Scan Script I maintain. This script can also be configured to be used for people who don’t use Newsgroups or NZBGet. I documented how this can be done through a cron on the GitHub link provided.
- NZBGet Scripting Framework I maintain. This provides the core of NZBGet’s version of Subliminal. It makes developing scripts for NZBGet really easy and is documented well explaining how to do so for those interested.