
Introduction
About a month ago I wrote (and updated) an article on how to install Nagios Core 4 onto your system. I’m a bit of a perfectionist, so I’ve rebuilt the packages a little to accommodate my needs. Now I thought it might be a good idea to introduce some of the powerful extensions you can get for Nagios.
For an updated solution, you may wish to check out the following:
- NRDP for Nagios Core on CentOS 7.x: This blog explains how awesome NRDP really is and why it might become a vital asset to your own environment. This tool can be used to replace NSCA’s functionality. The blog also provides the first set of working RPMs (with SELinux support of course) of it’s kind to support it.
- NRPE for Nagios Core on CentOS 7.x: This blog explains how to set up NRPE (v3.x) for your Nagios environment. At the time this blog was written, there was no packaging of it’s kind for this version.
RPM Solution
RPMs provide a version control and an automated set of scripts to configure the system how I want it. The beauty of them is that if you disagree with something the tool you’re packaging does, you can feed RPMs patch files to accommodate it without obstructing the original authors intention.
Now I won’t lie and claim I wrote these SPEC files from scratch because I certainly didn’t. I took the stock ones that ship with these products (NRPE and NSCA) and modified them to accommodate and satisfy my compulsive needs. 🙂
My needs required a bit more automation in the setup as well as including:
- A previous Nagios requirement I had was a /etc/nagios/conf.d directory to behave similar to how Apache works. I wanted to be able to drop configuration files into here and just have it work without re-adjusting configuration files. In retrospect of this, these plugins are a perfect example of what can use this folder and work right out of the box.
- These new Nagios plugins should adapt to the new nagiocmd permissions. The nagioscmd group permission was a Nagios requirement I had made in my previous blog specifically for the plugin access.
- NSCA should prepare some default configuration to make it easier on an administrator.
- NSCA servers that don’t respond within a certain time should advance to a critical state. This should be part of the default (optional) configuration one can use.
- Both NRPE and NSCA should plug themselves into Nagios silently without human intervention being required.
- Both NRPE and NSCA should log independently to their own controlled log file that is automatically rotated by the system when required.
Nagios Enhancement Focus
The key things I want to share with you guys that you may or may not find useful for your own environment are the following:
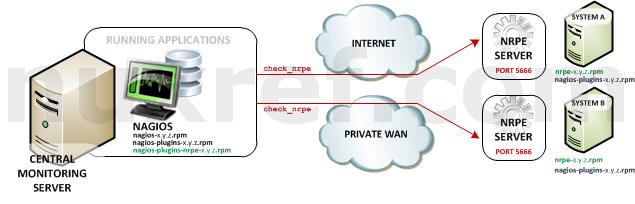
- Nagios Remote Plugin Executor (NRPE): NRPE (officially accessed here) provides a way to execute all of the Nagios monitoring tools on a remote server. These actions are all preformed through a secure (private) connection to the remote server and then reported back to Nagios. NRPE can allow you to monitor servers that are spread over a WAN (even the internet) from one central monitoring server. This is truly the most fantastic extension of Nagios in my opinion.
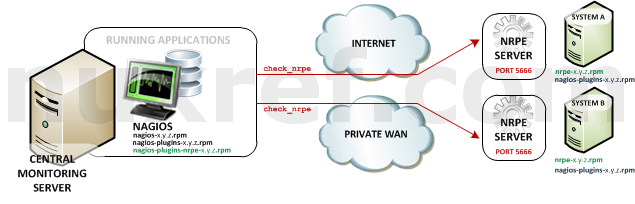
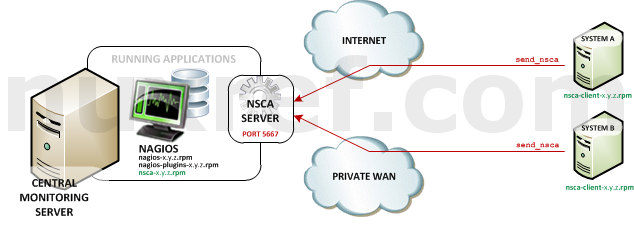
NRPE High Level Overview - Nagios Service Check Acceptor (NSCA): NSCA (officially accessed here) provides a way for external applications to report their status directly to the Nagios Server on their own. This solution still allows the remote monitoring of a system by taking the responsibility off of the status checks off of Nagios. However the fantastic features of Nagios are still applicable: You are still centrally monitoring your application and Nagios will immediately take action in notifying you if your application stops responding or reports a bad status. This solution is really useful when working with closed systems (where opening ports to other systems is not an option).
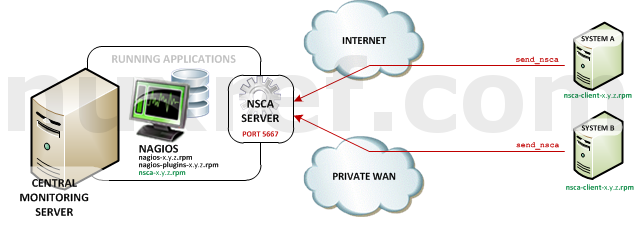
NSCA High Level Overview
Just give me your packaged RPMS
Here they are:
- NRPE
- Client (Nagios) Side: nagios-plugins-nrpe-2.15-1.el6.x86_64.rpm
- Server Side: nrpe-2.15-1.el6.x86_64.rpm
- Source: nrpe-2.15-1.el6.src.rpm (Optional)
- NSCA
- Server (Nagios) Side: nsca-2.7.2-9.el6.x86_64.rpm
- Client Side: nsca-client-2.7.2-9.el6.x86_64.rpm
- Source: nsca-2.7.2-9.el6.src.rpm (Optional)
How do I make these packages work for me?
In all cases, the RPMs take care of just about everything for you, so there isn’t really much to do at this point. Some considerations however are as follows:
- NRPE
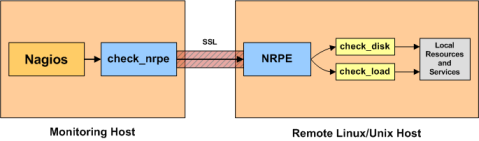
NRPE – Nagios Remote Plugin Executor
In an NRPE setup, Nagios is always the client and all of the magic happens when it uses the check_nrpe plugin. Most of NRPE’s configuration resides at the remote server that Nagios will monitor. In a nutshell, NRPE will provide the gateway to check a remote system’s status but in a much more secure and restrictive manor than the check_ssh which already comes with the nagios-plugins package. The check_ssh requires you to create a remote user account it can connect with for remote checks. This can leave your system vulnerable to an attack since you can do a lot more damage with a compromised SSH account. However check_nrpe uses the NRPE protocol and can only return what you let it; therefore making it a MUCH safer choice then check_ssh!You’ll want to install nagios-plugins-nrpe on the same server your hosting Nagios on:
# Download NRPE wget --output-document=nagios-plugins-nrpe-2.15-1.el6.x86_64.rpm http://repo.nuxref.com/centos/6/en/x86_64/custom/nagios-plugins-nrpe-2.15-4.el6.nuxref.x86_64.rpm # Now install it yum -y localinstall nagios-plugins-nrpe-2.15-1.el6.x86_64.rpm
Again I must stress, the above setup will work right away presuming you chose to use my custom build of Nagios introduced in my blog that went with it.
Just to show you how everything works, we’ll make the Nagios Server the NRPE Server as well. In real world scenario, this would not be the case at all! But feel free to treat the setup example below on a remote system as well because it’s configuration will be identical! 🙂
# Install our NRPE Server wget --output-document=nrpe-2.15-1.el6.x86_64.rpm http://repo.nuxref.com/centos/6/en/x86_64/custom/nrpe-2.15-4.el6.nuxref.x86_64.rpm # Install some Nagios Plugins we can configure NRPE to use wget --output-document=nagios-plugins-1.5-1.x86_64.rpm http://repo.nuxref.com/centos/6/en/x86_64/custom/nagios-plugins-1.5-5.el6.nuxref.x86_64.rpm # Now Install it yum -y localinstall nrpe-2.15-1.el6.x86_64.rpm nagios-plugins-1.5-1.x86_64.rpm # This tool requires xinetd to be running; start it if it isn't # already running service xinetd status || service xinetd start # Make sure our system will always start xinetd # even if it's rebooted chkconfig --level 345 xinetd on
Now we can test our server by creating a test configuration:
# Create a NRPE Configuration our server can accept cat << _EOF > /etc/nrpe.d/check_mail.cfg command[check_mailq]=/usr/lib64/nagios/plugins/check_mailq -c 100 -w 50 _EOF # Create a temporary test configuration to work with: cat << _EOF > /etc/nagios/conf.d/nrpe_test.cfg define service{ use local-service service_description Check Users host_name localhost # check_users is already defined for us in /etc/nagios/nrpe.cfg check_command check_nrpe!check_users } # Test our new custom one we just created above define service{ use local-service service_description Check Mail Queue host_name localhost # Use the new check_mailq we defined above in /etc/nrpe.d/check_mail.cfg check_command check_nrpe!check_mailq } _EOF # Reload Nagios so it sees our new configuration defined in # /etc/nagios/conf.d/* service nagios reload # Reload xinetd so nrpe sees our new configuration defined in # /etc/nrpe.d/* service xinetd reloadWe can even test our connection manually by calling the command:
# This is what the output will look like if everything is okay: /usr/lib64/nagios/plugins/check_nrpe -H localhost -c check_mailq OK: mailq is empty|unsent=0;50;100;0
Another scenario you might see (when setting on up on your remote server) is:
/usr/lib64/nagios/plugins/check_nrpe -H localhost -c check_mailq CHECK_NRPE: Error - Could not complete SSL handshake.
Uh oh, Could not complete SSL handshake.! What does that mean?
This is the most common error people see with the NRPE plugin. If you Google it, you’ll get an over-whelming amount of hits suggesting how you can resolve the problem. I found this link useful.
That all said, I can probably tell you right off the bat why it isn’t working for you. Assuming you’re using the packaging I provided then it’s most likely because your NRPE Server is denying the requests your Nagios Server is making to it.To fix this, access your NRPE Server and open up /etc/xinetd/nrpe in an editor of your choice. You need to allow your Nagios Server access by adding it’s IP address to the only_from entry. Or you can just type the following:
# Set your Nagios Server IP here: NAGIOS_SERVER=192.168.192.168 # If you want to keep your previous entries and append the server # you can do the following (spaces delimit the servers): sed -i -e "s|^(.*only_from[^=]+=)[ t]*(.*)|1 2 $NAGIOS_SERVER|g" /etc/xinetd.d/nrpe # The below command is fine too to just replace what is there # with the server of your choice (you can use either example sed -i -e "s|^(.*only_from[^=]+=).*|1 $NAGIOS_SERVER|g" /etc/xinetd.d/nrpe # When your done, restart xinetd to update it's configuration service xinetd reload
Those who didn’t receive the error I showed above, it’s only because your using your Nagios Server as your NRPE Server too (which the xinetd tool is pre-configured to accept by default). So please pay attention to this when you start installing the NRPE server remotely.
You will want to install nagios-plugins-nrpe on to your NRPE Server as well granting you access to all the same great monitoring tools that have already been proven to work and integrate perfectly with Nagios. This will save you a great deal of effort when setting up the NRPE status checks.
As a final note, you may want to make sure port 5666 is open on your NRPE Server’s firewall otherwise the Nagios Server will not be able to preform remote checks.
## Open NRPE Port (as root) iptables -A INPUT -m state --state NEW -m tcp -p tcp --dport 5666 -j ACCEPT # consider adding this change to your iptables configuration # as well so when you reboot your system the port is # automatically open for you. See: /etc/sysconfig/iptables # You'll need to add a similar line as above (without the # iptables reference) # -A INPUT -m state --state NEW -m tcp -p tcp --dport 5666 -j ACCEPT
- NSCA
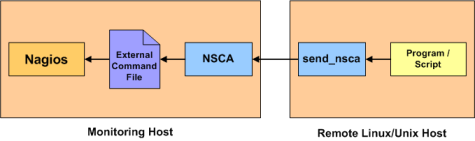
NSCA – Nagios Service Check Acceptor
Remember, NSCA is used for systems that connect to you remotely (instead of you connecting to them (what NRPE does). This is a perfect choice plugin for systems you do not want to open ports up to unnecessarily on your remote system. That said, it means you need to open up ports on your Monitoring (Nagios) server instead.You’ll want to install nsca on the same server your hosting Nagios on:
# Download NSCA wget --output-document=nsca-2.7.2-9.el6.x86_64.rpm http://repo.nuxref.com/centos/6/en/x86_64/custom/nsca-2.7.2-10.el6.nuxref.x86_64.rpm # Now install it yum -y localinstall nsca-2.7.2-9.el6.x86_64.rpm # This tool requires xinetd to be running; start it if it isn't # already running service xinetd status || service xinetd start # Make sure our system will always start xinetd # even if it's rebooted chkconfig --level 345 xinetd on # SELinux Users may wish to turn this flag on if they intend to allow it # to call content as root (using sudo) which it must do for some status checks. setsebool -P nagios_run_sudo on
The best way to test if everything is working okay is by also installing the nsca-client on the same machine we just installed NSCA on (above). Then we can simply create a test passive service to test everything with. The below setup will work presuming you chose to use my custom build of Nagios introduced in my blog that went with it.
# First install our NSCA client on the same machine we just installed NSCA # on above. wget http://repo.nuxref.com/centos/6/en/x86_64/custom/nsca-client-2.7.2-10.el6.nuxref.x86_64.rpm # Now install it yum -y localinstall nsca-client-2.7.2-9.el6.x86_64.rpm # Create a temporary test configuration to work with: cat << _EOF > /etc/nagios/conf.d/nsca_test.cfg # Define a test service. Note that the service 'passive_service' # is already predefined in /etc/nagios/conf.d/nsca.cfg which was # placed when you installed my nsca rpm define service{ use passive_service service_description TestMessage host_name localhost } _EOF # Now reload Nagios to it reads in our new configuration # Note: This will only work if you are using my Nagios build service nagios reloadNow that we have a test service set up, we can send it different nagios status through the send_nsca binary that was made available to us after installing nsca-client.
# Send a Critical notice to Nagios using our test service # and send_nsca. By default send_nsca uses the '<tab>' as a # delimiter, but that is hard to show in a blog (it can get mixed up # with the space. So in the examples below i add a -d switch # to adjust what the delimiter in the message. # The syntax is simple: # hostname,nagios_service,status_code,status_msg # # The test service we defined above identifies both the # 'host_name' and 'service_description' define our first 2 # delimited columns below. The status_code is as simple as: # 0 : Okay # 1 : Warning # 2 : Critical # The final delimited entry is just the human readable text # we want to pass a long with the status. # # Here we'll send our critical message: cat << _EOF | /usr/sbin/send_nsca -H 127.0.0.1 -d ',' localhost,TestMessage,2,This is a Test Error _EOF # Open your Nagios screen (http://localhost/nagios) at this point and watch the # status change (it can take up to 4 or 5 seconds or so to register # the command above). # Cool? Here is a warning message: cat << _EOF | /usr/sbin/send_nsca -H 127.0.0.1 -d ',' -c /etc/nagios/send_nsca.cfg localhost,TestMessage,1,This is a Test Warning _EOF # Check your warning on Nagios, when your happy, here is your # OKAY message: cat << _EOF | /usr/sbin/send_nsca -H 127.0.0.1 -d ',' -c /etc/nagios/send_nsca.cfg localhost,TestMessage,0,Life is good! _EOF
Since NSCA requires you to listen to a public port, you’ll need to know this last bit of information to complete your NSCA configuration. Up until now the package i provide only open full access to localhost for security reasons. But you’ll need to take the next step and allow your remote systems to talk to you.
NSCA uses port 5667, so you’ll want to make sure your firewall has this port open using the following command:
## Open NSCA Port (as root) iptables -A INPUT -m state --state NEW -m tcp -p tcp --dport 5667 -j ACCEPT # consider adding this change to your iptables configuration # as well so when you reboot your system the port is # automatically open for you. See: /etc/sysconfig/iptables # You'll need to add a similar line as above (without the # iptables reference) # -A INPUT -m state --state NEW -m tcp -p tcp --dport 5667 -j ACCEPT
Another security in place with the NSCA configuration you installed out of
the box is that it is being managed by xinetd. The configuration can
be found here: /etc/xinetd.d/nsca. The security restriction in place that you’ll want to pay close attention to is line 16 which reads:only_from = 127.0.0.1 ::1
If you remove this line, you’ll allow any system to connect to yours; this is a bit unsafe but an option. Personally, I recommend that you individually add each remote system you want to monitor to this line. Use a space to separate more the one system.
You can consider adding more security by setting up a NSCA paraphrase which will reside in /etc/nagios/nsca.cfg to which you can place the same paraphrase in all of the nsca-clients you set up by updating /etc/nagios/send_nsca.cfg.
Consider our example above; I can do the following to add a paraphrase:
# Configure Client sed -i -e 's/^#*password=/password=ABCDEFGHIJKLMNOPQRSTUVWXYZ/g' /etc/nagios/send_nsca.cfg # Configure Server sed -i -e 's/^#*password=/password=ABCDEFGHIJKLMNOPQRSTUVWXYZ/g' /etc/nagios/nsca.cfg # Reload xinetd so it rereads /etc/nagios/nsca.cfg service xinetd reload
I don’t trust you, I want to repackage this myself!
As always, I will always provide you a way to build the source code from scratch if you don’t want to use what I’ve already prepared. I use mock for everything I build so I don’t need to haul in development packages into my native environment. You’ll need to make sure mock is setup and configured properly first for yourself:
# Install 'mock' into your environment if you don't have it already. # This step will require you to be the superuser (root) in your native # environment. yum install -y mock # Grant your normal every day user account access to the mock group # This step will also require you to be the root user. usermod -a -G mock YourNonRootUsername
At this point it’s safe to change from the ‘root‘ user back to the user account you granted the mock group privileges to in the step above. We won’t need the root user again until the end of this tutorial when we install our built RPM.
Just to give you a quick summary of what I did, here are the new spec files and patch files I created:
- NSCA RPM SPEC File: Here is the enhanced spec file I used (enhancing the one already provided in the EPEL release found on pkgs.org). At the time I wrote this blog, the newest version of NSCA was v2.7.2-8. This is why I repackaged it as v2.7.2-9 to include my enhancements. I created 2 patches along with the spec file enhancements.
nrpe.conf.d.patch was created to provide a working NRPE configuration right out of the box (as soon as it was installed) and nrpe.xinetd.logrotate.patch was created to pre-configure a working xinetd server configuration. - NRPE RPM SPEC File: Here is the enhanced spec file I used (enhancing the one already provided in the EPEL release found on pkgs.org). At the time I wrote this blog, the newest version of NRPE was v2.14-5. However v2.15 was available off of the Nagios website so this is why I repackaged it as v2.15-1 to include my enhancements.
nsca.xinetd.logrotate.patch was the only patch I needed to create to prepare a NSCA xinetd server working out of the box.
Everything else packaged (patches and all) are the same ones carried forward from previous versions by their package managers.
Rebuild your external monitoring solutions:
Below shows the long way of rebuilding the RPMs from source.
# Perhaps make a directory and work within it so it's easy to find # everything later mkdir nagiosbuild cd nagiosbuild ### # Now we want to download all the requirements we need to build ### # Prepare our mock environment ### # Initialize Mock Environment mock -v -r epel-6-x86_64 --init # NRPE (v2.15) wget http://repo.nuxref.com/centos/6/en/source/custom/nrpe-2.15-4.el6.nuxref.src.rpm mock -v -r epel-6-x86_64 --copyin nrpe-2.15-1.el6.src.rpm /builddir/build # NSCA (v2.7.2) wget http://repo.nuxref.com/centos/6/en/source/custom/nsca-2.7.2-10.el6.nuxref.src.rpm mock -v -r epel-6-x86_64 --copyin nsca-2.7.2-9.el6.src.rpm /builddir/build ####################### ### THE SHORT WAY ##### ####################### # Now, the short way to rebuild everything is through these commands: mock -v -r epel-6-x86_64 --resultdir=$(pwd)/results --rebuild nrpe-2.15-1.el6.src.rpm nsca-2.7.2-9.el6.src.rpm # You're done; You can find all of your rpms in a results directory # in the same location you typed the above command in. You can # alternatively rebuild everything the long way allowing you to # inspect the content in more detail and even change it for your # own liking ####################### ### THE LONG WAY ##### ####################### # Install NRPE Dependencies mock -v -r epel-6-x86_64 --install autoconf automake libtool openssl-devel tcp_wrappers-devel # Install NSCA Dependencies mock -v -r epel-6-x86_64 --install tcp_wrappers-devel libmcrypt-devel ### # Build Stage ### # Shell into our enviroment mock -v -r epel-6-x86_64 --shell # Change to our build directory cd builddir/build # Install our SRPMS (within our mock jail) rpm -Uhi nsca-*.src.rpm nrpe-*.src.rpm # Now we'll have placed all our content in the SPECS and SOURCES # directory (within /builddir/build). Have a look to verify # content if you like # Build our RPMS rpmbuild -ba SPECS/*.spec # we're now done with our mock environment for now; Press Ctrl-D to # exit or simply type exit on the command line of our virtual # environment exit ### # Save our content that we built in the mock environment ### #NRPE mock -v -r epel-6-x86_64 --copyout /builddir/build/SRPMS/nrpe-2.15-1.el6.src.rpm . mock -v -r epel-6-x86_64 --copyout /builddir/build/RPMS/nrpe-2.15-1.el6.x86_64.rpm . mock -v -r epel-6-x86_64 --copyout /builddir/build/RPMS/nagios-plugins-nrpe-2.15-1.el6.x86_64.rpm . mock -v -r epel-6-x86_64 --copyout /builddir/build/RPMS/nrpe-debuginfo-2.15-1.el6.x86_64.rpm . #NSCA mock -v -r epel-6-x86_64 --copyout /builddir/build/SRPMS/nsca-2.7.2-9.el6.src.rpm . mock -v -r epel-6-x86_64 --copyout /builddir/build/RPMS/nsca-2.7.2-9.el6.x86_64.rpm . mock -v -r epel-6-x86_64 --copyout /builddir/build/RPMS/nsca-client-2.7.2-9.el6.x86_64.rpm . mock -v -r epel-6-x86_64 --copyout /builddir/build/RPMS/nsca-debuginfo-2.7.2-9.el6.x86_64.rpm . # *Note that all the commands that interact with mock I pass in # the -v which outputs a lot of verbose information. You don't # have to supply it; but I like to see what is going on at times. # **Note: You may receive this warning when calling the '--copyout' # above: # WARNING: unable to delete selinux filesystems # (/tmp/mock-selinux-plugin.??????): # # [Errno 1] Operation not permitted: '/tmp/mock-selinux-plugin.??????' # # This is totally okay; and is safe to ignore, the action you called # still worked perfectly; so don't panic!
So where do I go from here?
NRPE and NSCA are both fantastic solutions that can allow you to tackle any monitoring problem you ever had. In this blog here I focus specifically on Linux, but these tools are also available on Microsoft Windows as well. You can easily have 1 Nagios Server manage thousands of remote systems (of all operating system flavours). There are hundreds of fantastic tools to monitor all mainstream applications used today (Databases, Web Servers, etc). Even if your trying to support a custom application you wrote. If you can interface with your application using the command line interface, well then Nagios can monitor it for you. You only need to write a small script with this in mind:
- Your script should always have an exit code of 0 (zero) if everything is okay, 1 (one) if you want to raise a warning, and 2 (two) if you want to raise a critical alarm.
- No matter what the exit code is, you should also echo some kind of message that someone could easily interpret what is going on.
There is enough information in this blog to do the rest for you (as far as creating a Nagios configuration entry for it goes). If you followed the 2 rules above, then everything should ‘just work’. It’s truely that easy and powerful.
How do I decide if I need NSCA or NRPE?
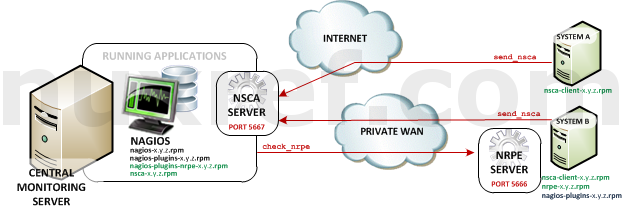
NRPE makes it Nagios’s responsibility to check your application where as NSCA makes it your applications responsible to report its status. Both have their pros and cons. NSCA could be considered the most secure approach because at the end of the day the only port that requires opening is the one on the Nagios server. NSCA does not use a completely secure connection (but there is encryption none the less). NRPE is very secure and doesn’t require you to really do much since it just simply works with the nagios-plugins already available. It litterally just extends these existing Nagios local checks to remote ones. NSCA requires you to configure a cron, or adjust your applications in such a way that it frequently calls the send_nsca command. NSCA can be a bit more difficult to set up but creates some what of a heartbeat between you and the system monitoring it (which can be a good thing too). I pre-configured the NSCA server with a small tweak that will automatically set your application to a critical state if a send_nsca call is missed for an extended period of time.
Always consider that the point of this blog was to state that you can use both at the same time giving you total flexibility over all of your systems that require monitoring.
Credit
All of the custom packaging in this blog was done by me personally. I took the open source available to me and rebuilt it to make it an easier solution and decided to share it. If you like what you see and wish to copy and paste this HOWTO, please reference back to this blog post at the very least. It’s really all I ask.
Sources
I referenced the following resources to make this blog possible:
- The blog I wrote earlier that is recommended you read before this one:Configuring and Installing Nagios Core 4 on CentOS 6
- Official NRPE download link; I used all of the official documentation to make the NRPE references on this blog possible.
- A document identifying the common errors you might see and their resolution here.
- Official NSCA download link; I used all of the official documentation to make the NSCA references on this blog possible.
- The NRPE and NSCA images I’m reposting on this blog were taking straight from their official sites mentioned above.
- Linux Packages Search (pkgs.org) was where I obtained the source RPMs as well as their old SPEC files. These would be a starting point before I’d expand them.
- A bit outdated, but a great (and simple) representation of how NSCA works with Nagios can be seen here.

